Abstract
Visual instruction tuning (VIT) datasets have grown rapidly in scale, yet the informativeness of individual training samples has largely been overlooked. We explore the impact of sample complexity on data curation and introduce COMPACT (COMPositional Atomic-to-complex Visual Compositional Tuning), a visual compositional tuning data recipe that scales training sample complexity by combining multiple atomic visual capabilities in a single training example.
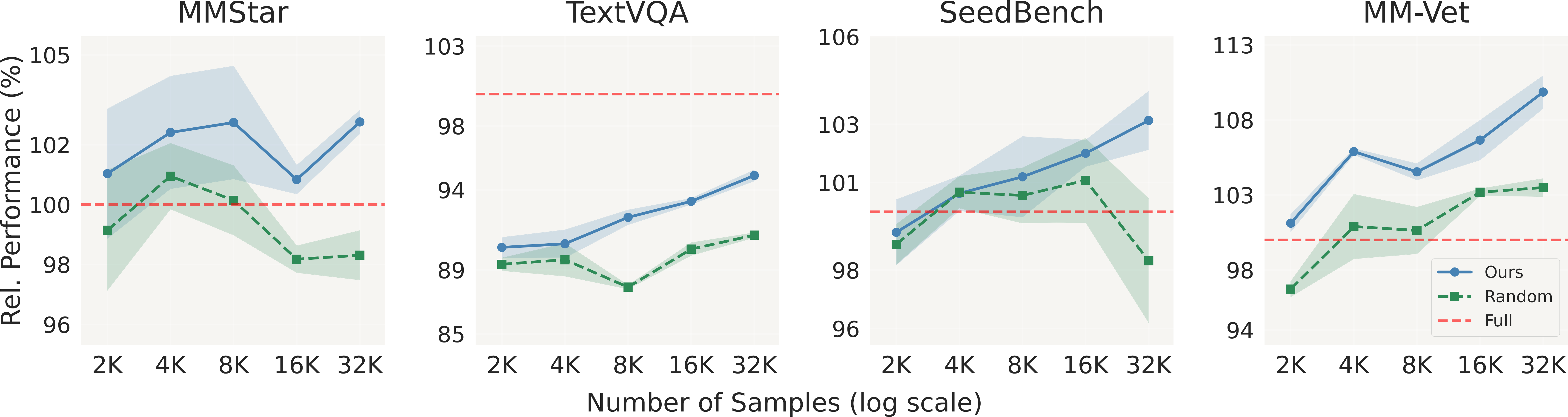
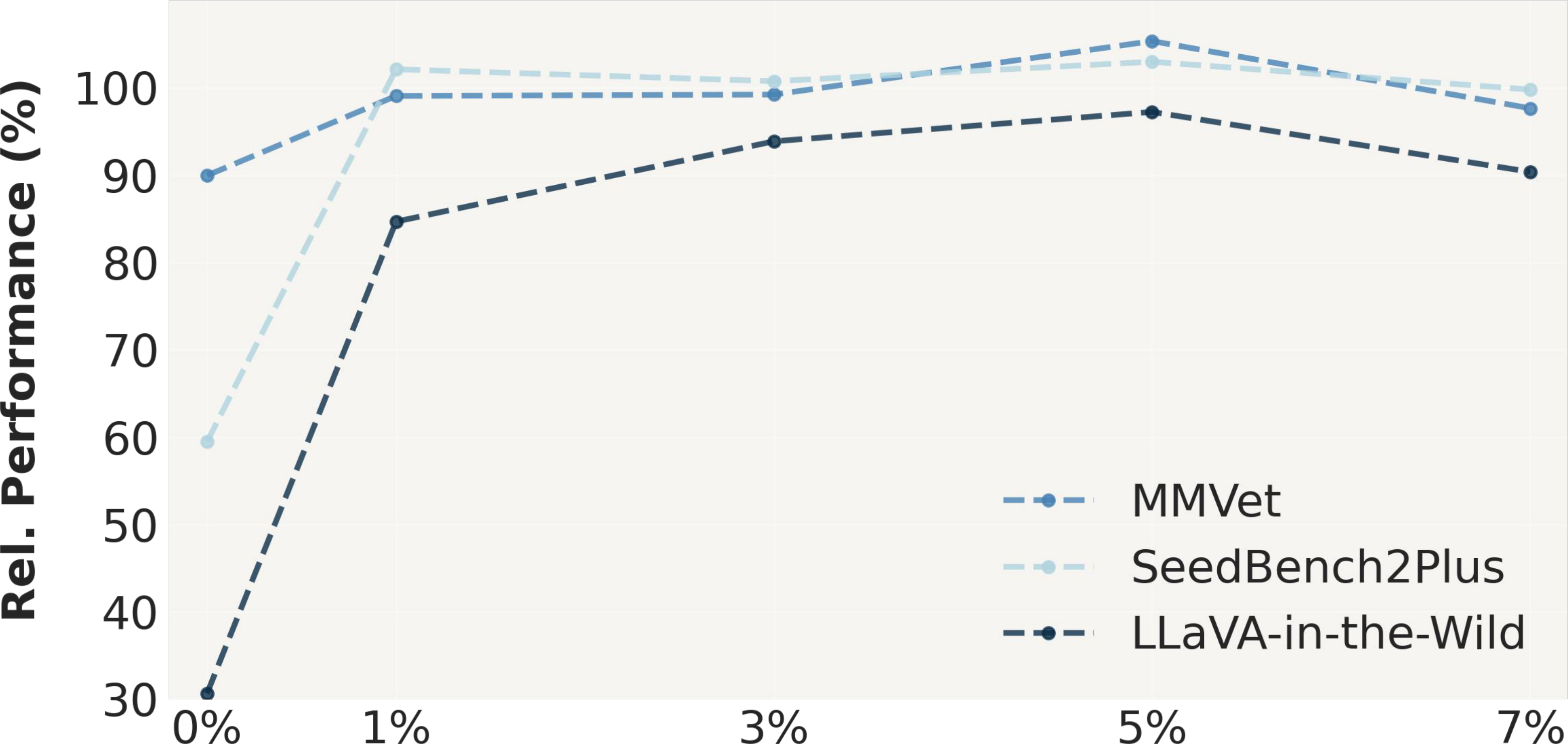
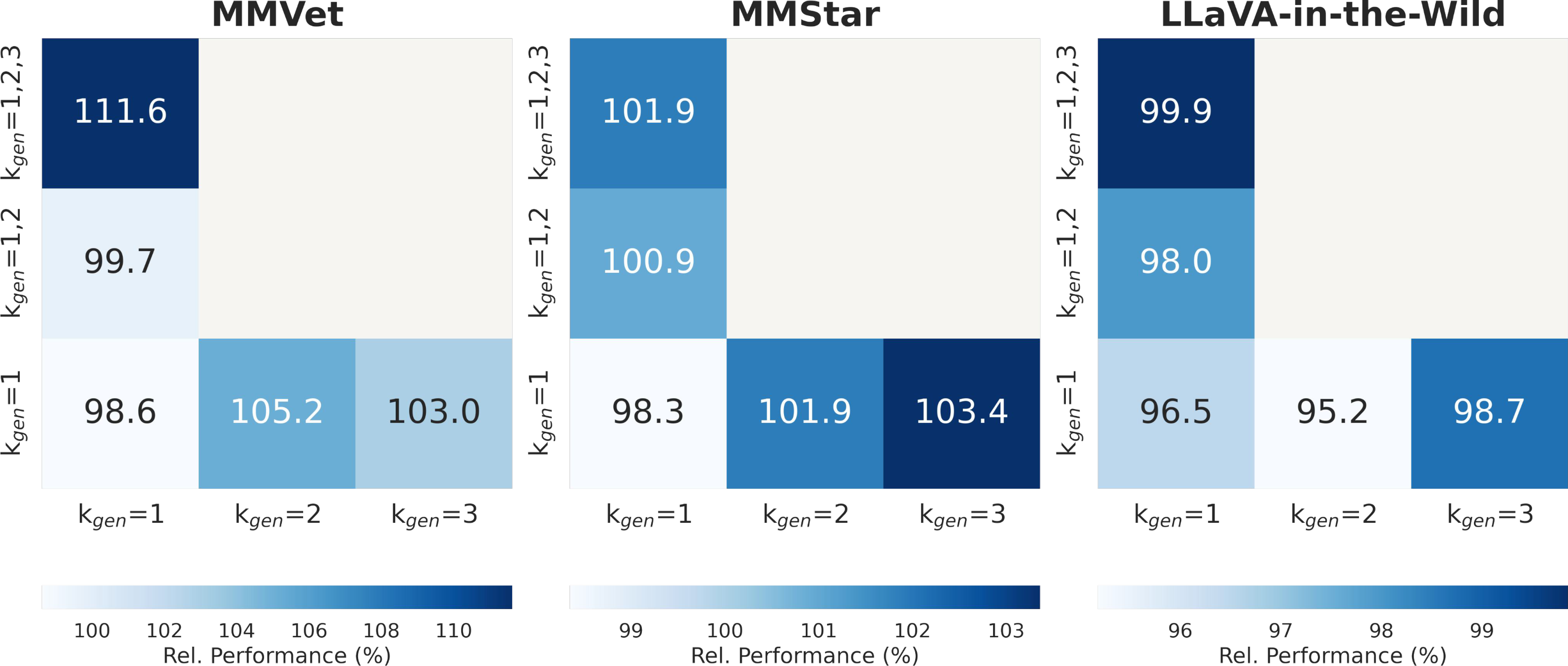
When applied to the LLaVA-665K VIT dataset, COMPACT reduces the data budget by 90% while still achieving 100.2% of the full VIT performance (compared to only 97.5% by the state-of-the-art method) across eight multimodal benchmarks. Training on COMPACT data outperforms training on the full-scale VIT data on complex benchmarks such as MM-Vet (+8.6%) and MMStar (+2.9%), offering a scalable and efficient synthetic data generation recipe for vision-language tasks.
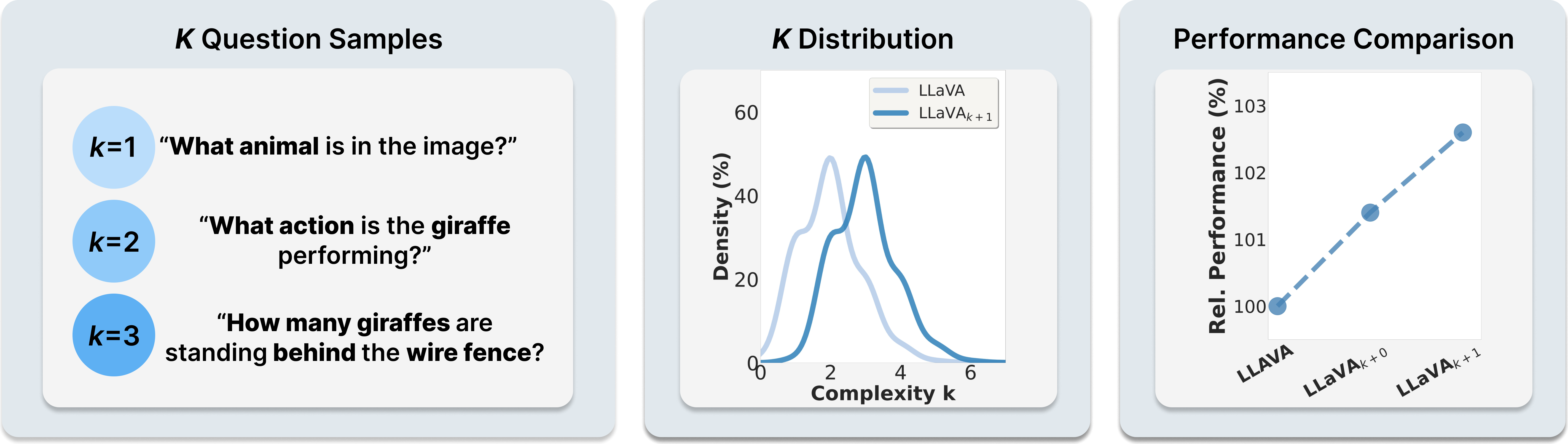
Complexity k. Increasing the complexity of LLaVA samples improves downstream performance. We define k as the number of atomic visual capabilities required to answer a question. Existing VIT datasets are dominated by simple (k ≤ 2) questions; augmenting samples with one additional capability (LLaVAk+1) shifts the distribution rightward and boosts accuracy.